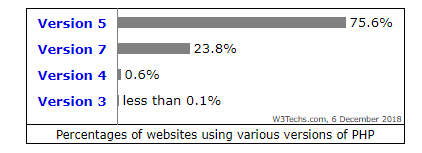
Ler o código de outras pessoas pode ser confuso. Podem passar horas para resolver problemas que poderiam ter sido corrigidos em minutos. Neste artigo, Artur Śmiarowski quer compartilhar dicas sobre como escrever códigos que serão mais fáceis de entender e manter.
Antes de começar, observe que este não é um guia para escrever "código limpo". As pessoas tendem a entender coisas diferentes com este termo, algumas preferem facilmente extensíveis e genéricas. Outros preferirão abstrair a implementação e apenas garantir a configuração e outros, que apenas querem ver um código subjetivamente bonito. Este guia se concentra na visibilidade do código. Com isso quero dizer um pedaço de código que comunica as informações necessárias para outros desenvolvedores, da forma mais eficiente possível.
Abaixo estão 23 princípios que ajudarão você a escrever um código mais legível. Este artigo é longo, não hesite em ir diretamente para as partes que lhe interessam.
Antes de começar, observe que este não é um guia para escrever "código limpo". As pessoas tendem a entender coisas diferentes com este termo, algumas preferem facilmente extensíveis e genéricas. Outros preferirão abstrair a implementação e apenas garantir a configuração e outros, que apenas querem ver um código subjetivamente bonito. Este guia se concentra na visibilidade do código. Com isso quero dizer um pedaço de código que comunica as informações necessárias para outros desenvolvedores, da forma mais eficiente possível.
Abaixo estão 23 princípios que ajudarão você a escrever um código mais legível. Este artigo é longo, não hesite em ir diretamente para as partes que lhe interessam.
II. Esteja ciente do seu problema antes de criar a solução▲
Se você corrige um bug, adiciona um novo recurso ou projeta um aplicativo, você resolve um problema para outra pessoa. Idealmente, você vai querer fazer isso, deixando o mínimo de anomalias atrás de você. Você deve ter clareza sobre os problemas que está resolvendo com suas escolhas de "padrão de design", retrabalho, dependências externas, bancos de dados e todas as outras coisas nas quais gasta tempo precioso.
Seu pedaço de código é um problema em potencial. Até o código mais bonito é. A única vez que um trecho de código não é mais um problema é quando um projeto é concluído e está inativo ou não é mais suportado. Por quê? Porque alguém terá que lê-lo durante sua vida, entendê-lo, corrigi-lo, estendê-lo ou mesmo remover completamente a funcionalidade que ele traz.
Manter o código básico leva muito tempo e poucos desenvolvedores gostam de fazê-lo porque falta criatividade. Escreva seu código da maneira mais simples possível para que um desenvolvedor júnior possa corrigi-lo quando necessário e você estará livre para lidar com problemas maiores.
A perda de tempo é um problema. Uma solução perfeita para sua tarefa pode estar disponível, mas às vezes é difícil para um desenvolvedor vê-la. Há tarefas para as quais a melhor solução é convencer o cliente de que o que ele procura não é necessariamente o que ele precisa. Isso requer um entendimento mais profundo do aplicativo e seu propósito. Seu cliente pode querer um módulo inteiro que eventualmente se tornará milhares de linhas adicionais de código, enquanto ele precisa apenas personalizar ainda mais suas opções existentes. Você pode precisar modificar apenas o código existente, economizando tempo e dinheiro.
Existem outros tipos de problemas. Digamos que você precise implementar uma lista de registros com filtros. Os dados são armazenados em um banco de dados, mas o link entre os diferentes registros é complexo. Depois de analisar como o cliente deseja que os dados sejam filtrados, você descobre que a complexidade do banco de dados exigirá 20 horas de criação de consultas SQL complexas, com várias associações e consultas internas. Por que não explicar que existe uma solução diferente que levará apenas uma hora, mas que não cobrirá toda a funcionalidade? Esse recurso adicional pode não justificar esse esforço, o que resultará em economia de custos.
Seu pedaço de código é um problema em potencial. Até o código mais bonito é. A única vez que um trecho de código não é mais um problema é quando um projeto é concluído e está inativo ou não é mais suportado. Por quê? Porque alguém terá que lê-lo durante sua vida, entendê-lo, corrigi-lo, estendê-lo ou mesmo remover completamente a funcionalidade que ele traz.
Manter o código básico leva muito tempo e poucos desenvolvedores gostam de fazê-lo porque falta criatividade. Escreva seu código da maneira mais simples possível para que um desenvolvedor júnior possa corrigi-lo quando necessário e você estará livre para lidar com problemas maiores.
A perda de tempo é um problema. Uma solução perfeita para sua tarefa pode estar disponível, mas às vezes é difícil para um desenvolvedor vê-la. Há tarefas para as quais a melhor solução é convencer o cliente de que o que ele procura não é necessariamente o que ele precisa. Isso requer um entendimento mais profundo do aplicativo e seu propósito. Seu cliente pode querer um módulo inteiro que eventualmente se tornará milhares de linhas adicionais de código, enquanto ele precisa apenas personalizar ainda mais suas opções existentes. Você pode precisar modificar apenas o código existente, economizando tempo e dinheiro.
Existem outros tipos de problemas. Digamos que você precise implementar uma lista de registros com filtros. Os dados são armazenados em um banco de dados, mas o link entre os diferentes registros é complexo. Depois de analisar como o cliente deseja que os dados sejam filtrados, você descobre que a complexidade do banco de dados exigirá 20 horas de criação de consultas SQL complexas, com várias associações e consultas internas. Por que não explicar que existe uma solução diferente que levará apenas uma hora, mas que não cobrirá toda a funcionalidade? Esse recurso adicional pode não justificar esse esforço, o que resultará em economia de custos.
III. Escolha a ferramenta de trabalho certa▲
Essa linguagem especial, a estrutura que você tanto ama ou um novo mecanismo de banco de dados, pode não ser a ferramenta certa para o problema que você está tendo. Em um projeto sério, não escolha ferramentas que você já ouviu falar como sendo fabuloso para tudo. Isso vai levar você ao desastre. Se seus dados precisarem de relacionamentos, escolher o MongoDB apenas para aprender terminará mal. Você sabe que pode fazer isso, mas muitas vezes precisará de uma solução alternativa que gere código adicional e forneça soluções que não são ideais. Claro, você pode dirigir um prego com uma tábua de madeira, mas uma busca rápida no google o mandaria de volta para um martelo.
IV. Simplicidade é rainha▲
Você já deve ter ouvido a frase "otimização prematura é a fonte de todo o mal". Ela tem uma verdade incompleta. Você deve preferir soluções simples, a menos que tenha certeza de que não funcionará, mas não acredite, você já deve ter verificado ou calculado anteriormente e ter certeza. Escolher uma solução mais complexa por qualquer motivo, velocidade de execução, falta de memória, falta de dependências ou qualquer outro motivo pode ter um impacto significativo na legibilidade do código. Não complique as coisas, a menos que você tenha que fazê-lo. A exceção a isso seria conhecer uma solução mais eficiente e saber que sua implementação não afetará a legibilidade e sua programação.
Da mesma forma, você não precisa usar todos os novos recursos do seu idioma se não beneficiar você e sua equipe. Novo, não significa melhor. Se você não tiver certeza, tente novamente no início e reconsidere o problema que está tentando resolver antes de fazer qualquer alteração. Se você precisar do índice de um loop, não é porque existem novas maneiras diferentes de escrever em Javascript que a sintaxe "for" é obsoleta.
Da mesma forma, você não precisa usar todos os novos recursos do seu idioma se não beneficiar você e sua equipe. Novo, não significa melhor. Se você não tiver certeza, tente novamente no início e reconsidere o problema que está tentando resolver antes de fazer qualquer alteração. Se você precisar do índice de um loop, não é porque existem novas maneiras diferentes de escrever em Javascript que a sintaxe "for" é obsoleta.
V. Suas funções, classes e componentes devem ter um objetivo claramente definido▲
Você conhece os princípios do " SOLID "? Achei prudente projetar biblioteca genérica, mas mesmo que eu usei algumas vezes e eu vi implementações em projetos, acho que as regras são um pouco confuso e complicado.
Divida seu código em funções para que cada um faça apenas uma coisa. Por exemplo, considere como podemos implementar um botão. Pode ser uma classe que agrupa todos os recursos de um botão. Você poderia implementar o botão com uma função para exibi-lo na tela, outro para destacá-lo quando for executado pelo mouse, depois outro para o clique do botão e outro para animá-lo ao clicar. Você pode dividi-lo ainda mais. Se você precisar calcular o retângulo da posição do botão com base na resolução da tela, não o faça na função de exibição. Implemente esse cálculo em uma classe diferente, pois ele poderá ser usado por outros elementos da IHM e usá-lo para exibir o botão.
É uma coisa simples de seguir, assim que você pensa "isso não tem nada a ver aqui", você pode movê-lo para outra função, fornecendo mais informações aos colegas encapsulando um bloco de código com um nome função e comentários.
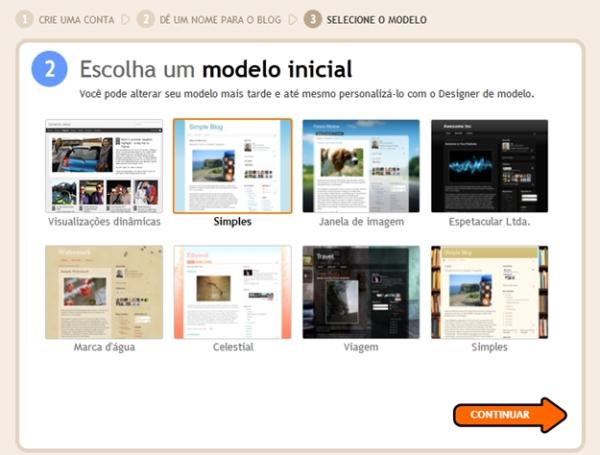
Examine os exemplos abaixo que fazem a mesma coisa, que informa o mais rapidamente possível do que faz?
Divida seu código em funções para que cada um faça apenas uma coisa. Por exemplo, considere como podemos implementar um botão. Pode ser uma classe que agrupa todos os recursos de um botão. Você poderia implementar o botão com uma função para exibi-lo na tela, outro para destacá-lo quando for executado pelo mouse, depois outro para o clique do botão e outro para animá-lo ao clicar. Você pode dividi-lo ainda mais. Se você precisar calcular o retângulo da posição do botão com base na resolução da tela, não o faça na função de exibição. Implemente esse cálculo em uma classe diferente, pois ele poderá ser usado por outros elementos da IHM e usá-lo para exibir o botão.
É uma coisa simples de seguir, assim que você pensa "isso não tem nada a ver aqui", você pode movê-lo para outra função, fornecendo mais informações aos colegas encapsulando um bloco de código com um nome função e comentários.
Examine os exemplos abaixo que fazem a mesma coisa, que informa o mais rapidamente possível do que faz?
selecionar
// C++
if (currentDistance < radius2) {
// C'est la vue du joueur
if (!isLight) {
// Si l'éclairage de la tuile est d'environ 30% (alors la vue dans l'obscurité est pire) ou la distance du joueur est de 1, la tuile devrait être visible.
if (hasInfravision || map.getLight(mapPosition) > 0.29f || ASEngine::vmath::distance(center, mapPosition) == 1) {
map.toggleVisible(true, mapPosition);
}
}
// Ceci est pour le calcul de l'éclairage
else {
ASEngine::ivec3 region = World::inst().map.currentPosition;
ASEngine::ivec2 pos = mapPosition;
if (mapPosition.x > 63) {
pos.x -= 64;
region.x += 1;
}
else if (mapPosition.x < 0) {
pos.x += 64;
region.x -= 1;
}
if (mapPosition.y > 63) {
pos.y -= 64;
region.y += 1;
}
else if (mapPosition.y < 0) {
pos.y += 64;
region.y -= 1;
}
map.changeLight(pos, region, 1.0f - static_cast(currentDistance) / static_cast(radius2));
}
}
selecionar
// C++
if (currentDistance < radius2) {
// C'est la vue du joueur
if (!isLight) {
this->markVisibleTile(hasInfravision, map, center, mapPosition);
}
// Ceci est pour le calcul de l'éclairage
else {
ASEngine::ivec3 region = World::inst().map.currentPosition;
ASEngine::ivec2 pos = map.getRelativePosition(mapPosition, region);
map.changeLight(pos, region, 1.0f - static_cast(currentDistance) / static_cast(radius2));
}
}VI. Naming é difícil, mas é importante▲
Os nomes das variáveis e funções devem ser distintos e fornecer uma ideia geral de seu uso. É importante que os nomes descrevam a utilidade para sua equipe e que eles estejam em conformidade com as convenções adotadas pelo projeto. Mesmo se você não concordar com eles. Se cada consulta para procurar um registro em um banco de dados começar com a palavra "find", como "findUser", sua equipe poderá ficar confusa se você nomear sua função "getUserProfile" porque está acostumado com ela. Tente agrupar os nomes sempre que possível. Por exemplo, se você tiver várias classes para validação de entrada, adicione "Validator", pois o sufixo de nome pode fornecer rapidamente informações sobre o propósito da classe.
Escolha e siga um tipo de caso padrão. Pode ser confuso acabar com um case de camelo (camelCase), um snake_case , um kebab-case (as letras estão em letras minúsculas e estão ligadas por traços) e um case de cerveja usado em diferentes arquivos do mesmo projeto.
Escolha e siga um tipo de caso padrão. Pode ser confuso acabar com um case de camelo (camelCase), um snake_case , um kebab-case (as letras estão em letras minúsculas e estão ligadas por traços) e um case de cerveja usado em diferentes arquivos do mesmo projeto.
VII. Não duplique o código▲
Já estabelecemos que o código é um problema. Então, por que duplicar seus problemas para ganhar alguns minutos? Não faz sentido. Você pode pensar que vai resolver algo rapidamente, simplesmente copiando e colando. Mas se você tiver que copiar mais de duas linhas de código, diga que pode perder uma oportunidade de encontrar uma solução melhor. Talvez uma função genérica ou um loop?
VIII. Remover código não utilizado, não deixá-la nos comentários▲
O código no comentário é confuso. Foi removido temporariamente? É importante? Quando foi comentado? É inútil, faça desaparecer. Eu entendo que você está hesitante em remover este código, porque as coisas podem dar errado e você só quer descomentar. Você pode até ser muito apegado a ele depois de todo o tempo e energia que você coloca nele. Ou talvez você ache que pode ser necessário "em breve". A solução para todos esses problemas é o software de versão. Use o histórico do GIT para encontrar o código, se precisar. E limpe depois de você!
IX. valores constantes devem ser lista constante ou estática▲
Você usa strings ou inteiros para definir os tipos de objetos? Por exemplo, um usuário pode ter uma função de "administrador" ou "convidado". Como você vai verificar se ele tem o papel de "administrador"?
Isso não é ótimo. Primeiro, se o nome "admin" mudar, você terá que modificá-lo em todo o aplicativo. Você poderia dizer que isso raramente acontece e os IDEs modernos facilitam a substituição. Isso mesmo. A outra razão é a ausência de autocomplete e erros de sintaxe podem ocorrer. Eles podem ser muito difíceis de depurar.
Ao definir constantes globais ou enumerações, dependendo do idioma usado, você pode aproveitar o preenchimento automático e editar um valor em um só lugar, caso precise dele. Você nem precisa lembrar que tipo de valor está oculto atrás da constante, apenas deixe fazer o EDI e a magia do autocomplete.
Não é apenas sobre o tipo de seus objetos. No PHP, você pode definir matrizes com strings como nomes de campos. Com estruturas complexas, pode ser difícil não cometer erros de tipo. E por esse motivo, é melhor usar objetos. Tente evitar codificar com strings e você fará menos erros de digitação e acelerará com o AutoComplete.
selecionar
if ($user->role == "admin") {
// L'utilisateur est un administrateur
}Ao definir constantes globais ou enumerações, dependendo do idioma usado, você pode aproveitar o preenchimento automático e editar um valor em um só lugar, caso precise dele. Você nem precisa lembrar que tipo de valor está oculto atrás da constante, apenas deixe fazer o EDI e a magia do autocomplete.
Não é apenas sobre o tipo de seus objetos. No PHP, você pode definir matrizes com strings como nomes de campos. Com estruturas complexas, pode ser difícil não cometer erros de tipo. E por esse motivo, é melhor usar objetos. Tente evitar codificar com strings e você fará menos erros de digitação e acelerará com o AutoComplete.
selecionar
// PHP
const ROLE_ADMIN = "admin";
if ($user->role == ROLE_ADMIN) {
// l'utilisateur est un administrateur
}
selecionar
// C++
enum class Role { GUEST, ADMIN }; // Il est possible de mapper ces énumérations vers des chaînes de caractères, mais ce n'est pas nécessaire.
if (user.role == Role.ADMIN) {
// l'utilisateur est un administrateur
}X. Prefere funções nativas a soluções personalizadas▲
Se o seu idioma ou estrutura que você selecionou para o seu projeto fornecer uma solução para o seu problema, use-o. Todos podem pesquisar rapidamente na Internet o que uma função faz, mesmo que não seja usada com frequência. Provavelmente, levará mais tempo para entender sua solução personalizada. Se você encontrar uma parte do código que faz a mesma coisa em uma função interna, refatore-a rapidamente, não a deixe como está. O código excluído não é mais um problema, por isso é importante excluí-lo!
XI. Use as recomendações específicas do idioma▲
Se você escrever em PHP, você deve conhecer os PSRs . Para Javascript, há uma recomendação decente do Airbnb . Para C ++, há uma recomendação do Google ou instruções básicas de Bjarne Stroustrup, o criador do C ++. Outros idiomas também devem ter suas próprias recomendações para a qualidade do código e você pode até mesmo fornecer seus próprios padrões para sua equipe. A importância é fortalecer o uso de recomendaçõesescolhido para o projeto, para que haja uma visão unificada de como ele deve ser desenvolvido. Isso evita muitos problemas de pessoas diferentes com experiências únicas e fazendo o que eles estão acostumados.
XII. Evitar a criação de blocos de código aninhados um no outro▲
Compare esses dois blocos de código:
O segundo é mais fácil de ler, não é? Se tal solução for possível, evite aninhar os blocos condicionais e os loops entre si. Um truque é inverter a instrução "if" e retornar à função de chamada antes de prosseguir para o próximo código, como no exemplo acima.
selecionar
void ProgressEffects::progressPoison(Entity entity,
std::shared_ptr<Effects> effects) {
float currentTime = DayNightCycle::inst().getCurrentTime();
if (effects->lastPoisonTick > 0.0f
&& currentTime > effects->lastPoisonTick + 1.0f) {
if (effects->poison.second > currentTime) {
std::shared_ptr < Equipment > eq = nullptr;
int poisonResitance = 0;
if (this->manager.entityHasComponent(entity, ComponentType::EQUIPMENT)) {
eq = this->manager.getComponent < Equipment > (entity);
for (size_t i = 0; i < EQUIP_SLOT_NUM; i++) {
if (eq->wearing[i] != invalidEntity
&& this->manager.entityHasComponent(eq->wearing[i],
ComponentType::ARMOR)) {
std::shared_ptr < Armor > armor = this->manager.getComponent < Armor
> (eq->wearing[i]);
poisonResitance += armor->poison;
}
}
}
int damage = effects->poison.first - poisonResitance;
if (damage < 1)
damage = 1;
std::shared_ptr < Health > health = this->manager.getComponent < Health
> (entity);
health->health -= damage;
} else {
effects->poison.second = -1.0f;
}
}
}
selecionar
void ProgressEffects::progressPoison(Entity entity, std::shared_ptr effects)
{
float currentTime = DayNightCycle::inst().getCurrentTime();
if (effects->lastPoisonTick < 0.0f || currentTime < effects->lastPoisonTick + 1.0f) return;
if (effects->poison.second <= currentTime) {
effects->poison.second = -1.0f;
return;
}
int poisonResitance = this->calculatePoisonResistance(entity);
int damage = effects->poison.first - poisonResitance;
if (damage < 1) damage = 1;
std::shared_ptr health = this->manager.getComponent(entity);
health->health -= damage;
}XIII. Não é o número de linhas que representam▲
Costumamos dizer que um pedaço de código que leva o menor número de linhas para realizar a tarefa é melhor. Alguns de nós ficam obcecados com o número de linhas de código que adicionamos ou removemos, medindo nossa produtividade por esse número. Fazemos isso para simplificação, mas não é uma regra que deve ser seguida sem levar em conta a legibilidade. Você pode reduzi-lo a uma única linha de código, mas é provável que seja mais difícil de entender do que se separar em algumas linhas simples com apenas um comando por linha.
Os idiomas fornecem a capacidade de escrever expressões condicionais curtas, como:
Pode ser uma boa escolha, mas também pode ser exagerada:
Deve ser mais fácil de entender após o desenvolvimento:
Essas três linhas ocupam mais espaço na tela, mas leva menos tempo para analisar o que é feito com os dados.
Os idiomas fornecem a capacidade de escrever expressões condicionais curtas, como:
selecionar
$variable == $x ? $y : $z; // if ($variable == x) { $result = $y; } else { $result = $z; }
selecionar
$variable == $x ? ($x == $y ? array_merge($x, $y, $z) : $x) : $y; // Pardon ???
selecionar
$result = $y;
if ($variable == $x && $x == $y) $result = array_merge($x, $y, $z);
else if ($variable == $x) $result = $x;XIV. Aprenda os modelos de design e quando não usá-los▲
Existem diferentes modelos de design que são frequentemente escolhidos para resolver problemas de desenvolvimento. Embora possam resolver problemas específicos, deve-se ter em mente que sua utilidade pode ser afetada por vários fatores, como o tamanho do projeto, o número de pessoas trabalhando lá, as restrições de tempo (custo) ou a complexidade necessária do projeto. a solução. Alguns modelos foram denominados anti-modelos, como o Singleton, porque, mesmo que forneçam soluções, também introduzem problemas em alguns casos.
Certifique-se de entender o custo da implementação em termos de complexidade introduzida antes de escolher um modelo de design para sua solução. Você pode não precisar de um modelo "Observador" para se comunicar entre componentes em um único sistema. Alguns booleanos podem ser uma solução fácil de seguir. É mais apropriado gastar tempo implementando um modelo de design selecionado em um aplicativo maior e mais complexo.
Certifique-se de entender o custo da implementação em termos de complexidade introduzida antes de escolher um modelo de design para sua solução. Você pode não precisar de um modelo "Observador" para se comunicar entre componentes em um único sistema. Alguns booleanos podem ser uma solução fácil de seguir. É mais apropriado gastar tempo implementando um modelo de design selecionado em um aplicativo maior e mais complexo.
XV. Separe suas aulas em gerenciador de dados e manipulador de dados▲
Um gerenciador de classes de dados é uma classe que contém dados em sua estrutura interna. Permite o acesso aos dados via accessors (getters) e mutators (setters) conforme necessário, mas não manipula os dados a menos que sejam modificados quando você os mantém no sistema ou se eles devem sempre ser modificados quando acesso.
Um bom exemplo está no modelo de arquitetura Entity Component System , em que os componentes contêm apenas os dados e os processos do sistema e os manipulam. Outro caso de uso seria o padrão de design "Armazém" implementado para comunicação com um banco de dados externo, em que uma classe "Modelo" representa os dados do banco de dados com uma estrutura de linguagem específica e a classe "Armazém" sincroniza dados com um banco de dados, passando as alterações de volta ao modelo ou recuperando os dados.
Essa separação facilita a compreensão das diferentes partes do seu aplicativo. Pegue o exemplo acima do armazém. Se você deseja exibir uma lista de dados contidos em uma coleção de "Modelos", você precisa saber de onde os dados vêm? Você precisa saber como os dados são armazenados no banco de dados e como eles precisam estar relacionados a estruturas específicas do idioma? Não. Você recupera os "Modelos" através dos métodos existentes e você se concentra apenas na sua tarefa, exibe os dados.
E quanto ao exemplo do Entity Component System ? Se você precisar implementar sistemas que gerenciam o uso de uma habilidade, reproduza animações, som, cause dano e assim por diante. Você não precisa saber como a habilidade foi ativada. Não importa se um script de AI iniciou a habilidade sob certas condições ou se um jogador usou uma tecla de atalho para ativá-lo. A única coisa que você precisa saber é que os dados de "Componente" foram alterados, indicando qual habilidade deve ser gerenciada.
Um bom exemplo está no modelo de arquitetura Entity Component System , em que os componentes contêm apenas os dados e os processos do sistema e os manipulam. Outro caso de uso seria o padrão de design "Armazém" implementado para comunicação com um banco de dados externo, em que uma classe "Modelo" representa os dados do banco de dados com uma estrutura de linguagem específica e a classe "Armazém" sincroniza dados com um banco de dados, passando as alterações de volta ao modelo ou recuperando os dados.
Essa separação facilita a compreensão das diferentes partes do seu aplicativo. Pegue o exemplo acima do armazém. Se você deseja exibir uma lista de dados contidos em uma coleção de "Modelos", você precisa saber de onde os dados vêm? Você precisa saber como os dados são armazenados no banco de dados e como eles precisam estar relacionados a estruturas específicas do idioma? Não. Você recupera os "Modelos" através dos métodos existentes e você se concentra apenas na sua tarefa, exibe os dados.
E quanto ao exemplo do Entity Component System ? Se você precisar implementar sistemas que gerenciam o uso de uma habilidade, reproduza animações, som, cause dano e assim por diante. Você não precisa saber como a habilidade foi ativada. Não importa se um script de AI iniciou a habilidade sob certas condições ou se um jogador usou uma tecla de atalho para ativá-lo. A única coisa que você precisa saber é que os dados de "Componente" foram alterados, indicando qual habilidade deve ser gerenciada.
XVI. Corrigir problemas em sua raiz▲
Você precisa implementar um novo recurso, adicionando-o ao código existente. Neste código você tem um problema. A estrutura de entrada da função não funciona adequadamente com suas necessidades. Então você tem que escrever um pouco mais de código para reorganizar os dados e extrair mais antes de implementar sua solução.
Antes de fazer isso, tente voltar alguns passos no seu código. De onde vêm esses dados e como eles são usados? Você pode, talvez, recuperá-los mais facilmente de uma fonte externa ou modificá-los assim que eles são adquiridos? Ao corrigir este problema na sua raiz, você pode resolver o mesmo problema em muitos lugares e para futuros recursos ou modificações. Sempre tente simplificar a maneira como você armazena seus dados para facilitar o acesso assim que recebê-los. Isso é especialmente importante quando os dados vêm de uma fonte externa. Se você precisar de dados de usuários do aplicativo ou APIs externas, deverá eliminar itens desnecessários e reordenar o restante imediatamente.
Antes de fazer isso, tente voltar alguns passos no seu código. De onde vêm esses dados e como eles são usados? Você pode, talvez, recuperá-los mais facilmente de uma fonte externa ou modificá-los assim que eles são adquiridos? Ao corrigir este problema na sua raiz, você pode resolver o mesmo problema em muitos lugares e para futuros recursos ou modificações. Sempre tente simplificar a maneira como você armazena seus dados para facilitar o acesso assim que recebê-los. Isso é especialmente importante quando os dados vêm de uma fonte externa. Se você precisar de dados de usuários do aplicativo ou APIs externas, deverá eliminar itens desnecessários e reordenar o restante imediatamente.
XVII. As armadilhas de abstração oculta▲
Por que escrevemos soluções gerais e abstratas para nossos problemas? Estender facilmente nossos aplicativos, facilitar a adaptação a novas necessidades e reutilizar nossas dicas de código, para que não seja necessário reescrevê-las.
Muitas vezes há um custo significativo para a abstração em termos de legibilidade. O nível mais alto de abstração é quando tudo é resolvido enquanto a implementação está oculta. Você tem a capacidade de configurar como processar seus dados recebidos, mas não tem controle sobre os detalhes, como eles serão armazenados no banco de dados, a eficiência com que serão processados, quais informações serão registradas etc. A vantagem dessa solução é que, se uma nova fonte de dados for tratada da mesma maneira que a fonte atual, é fácil configurá-la com a biblioteca e selecionar o local de armazenamento. Você basicamente negocia a velocidade do controle de implementação.
Quando algo dá errado e não é um problema devidamente documentado, alguém terá dificuldade em entender todas as idéias de propósito geral que estão tentando resolver muito mais do que o necessário. Se pudermos permitir, devemos evitar ocultar os detalhes da implementação. Manter o controle sobre o banco de dados permite mais flexibilidade. Não escreva uma solução geral para um problema simples apenas porque você acha que ela poderia ser estendida no futuro. Este raramente é o caso e pode ser reescrito quando necessário.
Vamos dar um exemplo: se você criar uma classe, em 10-15 linhas de códigos legíveis, que importam dados de um arquivo CSV e os armazenam em um banco de dados, por que se preocupar em fazer duas classes e generalizar a solução para que poderia ser estendido para importar XLS ou XML no futuro, quando você nem sequer tem idéia se será necessário para sua aplicação? Por que arrastar uma biblioteca externa de 5000 linhas de código que você não precisa resolver esse problema?
Raramente é necessário tornar genérico o local de armazenamento de seus dados. Quantas vezes em sua carreira você mudou seu mecanismo de banco de dados? Nos últimos dez anos, só encontrei uma vez um problema que foi resolvido dessa maneira. Criar soluções abstratas é caro e muitas vezes inútil, a menos que seja para uma biblioteca que tenha que lidar com uma ampla variedade de projetos de uma só vez.
Por outro lado, quando você tem certeza de que precisa permitir a importação de arquivos XLS e CSV, a solução geral deve ser uma opção perfeitamente viável. Também é possível escrever uma solução geral mais tarde, quando os requisitos da sua aplicação mudarem. Será muito mais fácil para uma pessoa ter uma solução simples e clara quando precisar substituí-la.
Muitas vezes há um custo significativo para a abstração em termos de legibilidade. O nível mais alto de abstração é quando tudo é resolvido enquanto a implementação está oculta. Você tem a capacidade de configurar como processar seus dados recebidos, mas não tem controle sobre os detalhes, como eles serão armazenados no banco de dados, a eficiência com que serão processados, quais informações serão registradas etc. A vantagem dessa solução é que, se uma nova fonte de dados for tratada da mesma maneira que a fonte atual, é fácil configurá-la com a biblioteca e selecionar o local de armazenamento. Você basicamente negocia a velocidade do controle de implementação.
Quando algo dá errado e não é um problema devidamente documentado, alguém terá dificuldade em entender todas as idéias de propósito geral que estão tentando resolver muito mais do que o necessário. Se pudermos permitir, devemos evitar ocultar os detalhes da implementação. Manter o controle sobre o banco de dados permite mais flexibilidade. Não escreva uma solução geral para um problema simples apenas porque você acha que ela poderia ser estendida no futuro. Este raramente é o caso e pode ser reescrito quando necessário.
Vamos dar um exemplo: se você criar uma classe, em 10-15 linhas de códigos legíveis, que importam dados de um arquivo CSV e os armazenam em um banco de dados, por que se preocupar em fazer duas classes e generalizar a solução para que poderia ser estendido para importar XLS ou XML no futuro, quando você nem sequer tem idéia se será necessário para sua aplicação? Por que arrastar uma biblioteca externa de 5000 linhas de código que você não precisa resolver esse problema?
Raramente é necessário tornar genérico o local de armazenamento de seus dados. Quantas vezes em sua carreira você mudou seu mecanismo de banco de dados? Nos últimos dez anos, só encontrei uma vez um problema que foi resolvido dessa maneira. Criar soluções abstratas é caro e muitas vezes inútil, a menos que seja para uma biblioteca que tenha que lidar com uma ampla variedade de projetos de uma só vez.
Por outro lado, quando você tem certeza de que precisa permitir a importação de arquivos XLS e CSV, a solução geral deve ser uma opção perfeitamente viável. Também é possível escrever uma solução geral mais tarde, quando os requisitos da sua aplicação mudarem. Será muito mais fácil para uma pessoa ter uma solução simples e clara quando precisar substituí-la.
XVIII. As regras do mundo não são as regras da sua aplicação▲
Eu tive um argumento interessante sobre a modelagem do "mundo real" ao implementar o paradigma OOP em um aplicativo. Digamos que tenhamos que processar dados grandes para um sistema de anúncios. Existem dois tipos de mensagens "log". O primeiro, que contém dados sobre a emissão de um anúncio. O segundo, que contém os mesmos dados que o show e alguns campos adicionais, informa às pessoas cliques no anúncio.
No mundo real, poderíamos considerar as duas ações, visualizar e clicar em um anúncio como separado, mas semelhante. Então, modelando o mundo real, poderíamos criar uma classe "Log" básica que estenderíamos para as classes "ClickLog" e "EmissionLog", conforme abaixo:
O exemplo acima mostra muito bem como o sistema funciona no mundo real. Emitir um anúncio é completamente diferente de alguém clicar nele. No entanto, essa escolha não fornece informações importantes. Em nosso aplicativo, qualquer coisa que possa processar um "log" de transmissão pode funcionar em cliques. Podemos usar as mesmas classes para lidar com as duas, mas apenas certos processadores "log" de cliques não podem trabalhar nos logs de transmissão, devido à diferença nos dados.
Em nossa aplicação, diferente do mundo real, nossa classe "ClickLog" é uma extensão do "EmissionLog". Eles podem ser tratados da mesma maneira, usando as classes que funcionam no "EmissionLog". Ao estender a classe "ClickLog" de "EmissionLog", você informa seus colegas que qualquer coisa que possa acontecer a um programa pode chegar a cliques, sem que eles precisem conhecer todos os possíveis processadores "log" em a aplicação.
No mundo real, poderíamos considerar as duas ações, visualizar e clicar em um anúncio como separado, mas semelhante. Então, modelando o mundo real, poderíamos criar uma classe "Log" básica que estenderíamos para as classes "ClickLog" e "EmissionLog", conforme abaixo:
selecionar
struct Log {
int x;
int y;
int z;
}
struct EmissionLog : public Log {}
struct ClickLog : public Log {
float q;
}Em nossa aplicação, diferente do mundo real, nossa classe "ClickLog" é uma extensão do "EmissionLog". Eles podem ser tratados da mesma maneira, usando as classes que funcionam no "EmissionLog". Ao estender a classe "ClickLog" de "EmissionLog", você informa seus colegas que qualquer coisa que possa acontecer a um programa pode chegar a cliques, sem que eles precisem conhecer todos os possíveis processadores "log" em a aplicação.
selecionar
struct EmissionLog {
int x;
int y;
int z;
}
struct ClickLog : public EmissionLog {
float q;
}XIX. Typez suas variáveis, se puder, mesmo se você não tem que fazer o▲
Você pode passar essa regra apenas se estiver programando em idiomas com tipos estáticos. Em linguagens dinamicamente tipificadas, como PHP ou Javascript, pode ser muito difícil entender o que uma parte do código deve fazer sem ver o conteúdo das variáveis. Pela mesma razão, o código pode ser muito imprevisível quando uma única variável pode ser um objeto, uma matriz ou nulo, dependendo de determinadas condições. Permitir o menor número possível de variáveis em suas configurações de função. Soluções estão disponíveis. O PHP pode ter argumentos e retornos tipados desde a versão 7. E você pode usar o Typescript em vez do Javascript. Isso ajuda a legibilidade do código e evita erros bobos.
Se você não precisar, não permita o uso de "Nulo" também. "Nulo" é uma abominação. Sua existência deve ser explicitamente verificada para evitar erros fatais que exigem código inútil. As coisas são ainda mais terríveis em Javascript com o seu "null" e "indefinido". Marque as variáveis que podem ser nulas para informar seus colegas:
Se você não precisar, não permita o uso de "Nulo" também. "Nulo" é uma abominação. Sua existência deve ser explicitamente verificada para evitar erros fatais que exigem código inútil. As coisas são ainda mais terríveis em Javascript com o seu "null" e "indefinido". Marque as variáveis que podem ser nulas para informar seus colegas:
XX. Escrever testes▲
Ao longo dos anos e evitando o esgotamento, estamos progredindo ao ponto de podermos mapear os recursos mais complexos em nossas mentes e implementá-los sem verificar se o código funciona até que o primeiro rascunho seja totalmente implementado. . Neste ponto, pode parecer uma perda de tempo escrever no ciclo TDD, porque é um pouco mais lento verificar cada coisa antes de escrevê-la. É uma boa prática escrever testes de integração que permitam que a funcionalidade funcione como esperado, simplesmente porque você provavelmente deixará alguns erros pequenos e poderá verificar tudo isso em alguns milissegundos.
Se você ainda não está familiarizado com seu idioma ou biblioteca e está tentando abordagens diferentes para resolver seu problema, pode ganhar muito com a redação de testes . Isso incentiva a divisão do trabalho em partes mais gerenciáveis. Os testes de integração rapidamente explicam quais tipos de problemas o código resolve, o que pode fornecer informações mais rapidamente do que uma implementação genérica. Um simples "esta entrada impulsiona essa saída" pode acelerar o processo de compreensão do aplicativo.
Se você ainda não está familiarizado com seu idioma ou biblioteca e está tentando abordagens diferentes para resolver seu problema, pode ganhar muito com a redação de testes . Isso incentiva a divisão do trabalho em partes mais gerenciáveis. Os testes de integração rapidamente explicam quais tipos de problemas o código resolve, o que pode fornecer informações mais rapidamente do que uma implementação genérica. Um simples "esta entrada impulsiona essa saída" pode acelerar o processo de compreensão do aplicativo.
XXI. Use ferramentas de análise de código estático▲
Existem muitas ferramentas de código aberto para análise de código estático. Muito disso também é fornecido em tempo real por IDE IDEs com recursos avançados. Eles ajudam a manter seus projetos nos trilhos. Você pode automatizar alguns deles em seus pipelines de armazenamento para que eles sejam executados em todos os "commit" em um ambiente "docker".
Escolhas sólidas para PHP:
- Copiar / colar detector ;
- PHP Mess Detector - verifica potenciais bugs e complexidade;
- PHP Code Sniffer - verifica os padrões de desenvolvimento;
- PHPMetrics - ferramenta de análise estática com painel e gráficos.
Javascript:
- JsHint / JsLint - procura por erros e problemas potenciais, pode ser integrado em um EDI para análise em tempo real;
- Platão - visualização de código fonte e ferramenta de complexidade.
C ++:
- Cppcheck - detecta bugs e comportamentos indefinidos;
- OClint - aumenta a qualidade do código.
Ferramenta que suporta diferentes idiomas:
- Pmd - detector de distúrbios.
Escolhas sólidas para PHP:
- Copiar / colar detector ;
- PHP Mess Detector - verifica potenciais bugs e complexidade;
- PHP Code Sniffer - verifica os padrões de desenvolvimento;
- PHPMetrics - ferramenta de análise estática com painel e gráficos.
Javascript:
- JsHint / JsLint - procura por erros e problemas potenciais, pode ser integrado em um EDI para análise em tempo real;
- Platão - visualização de código fonte e ferramenta de complexidade.
C ++:
- Cppcheck - detecta bugs e comportamentos indefinidos;
- OClint - aumenta a qualidade do código.
Ferramenta que suporta diferentes idiomas:
- Pmd - detector de distúrbios.
XXII. Revisão por pares▲
O replay de código é feito simplesmente por outro desenvolvedor que examina seu código em busca de erros e ajuda a melhorar a qualidade do software. Embora eles possam contribuir para a qualidade geral do aplicativo e permitir um fluxo de conhecimento dentro da equipe, eles são úteis apenas se todos estiverem abertos a críticas construtivas. Às vezes, as pessoas que releem impõem sua visão e experiência e não aceitam um ponto de vista diferente, o que também pode ser difícil de aceitar.
Pode ser difícil ter sucesso dependendo do ambiente da equipe, mas a recompensa pode ser incrível. O maior e mais limpo aplicativo que já participei no desenvolvimento foi feito com revisões de código muito completas.
Pode ser difícil ter sucesso dependendo do ambiente da equipe, mas a recompensa pode ser incrível. O maior e mais limpo aplicativo que já participei no desenvolvimento foi feito com revisões de código muito completas.
XXIII. Comentários▲
Você já deve ter notado que eu gosto de manter regras de codificação simples, para que sejam fáceis para toda a equipe seguir. É o mesmo com os comentários.
Acredito que os comentários devem ser adicionados a cada função, incluindo construtores, a cada propriedade de classe, constante estática e a cada classe. É uma questão de disciplina. Quando você permite a preguiça, permitindo exceções aos comentários quando "algo não requer comentário, porque é auto-explicativo", a preguiça é muitas vezes o que você recebe.
O que quer que você pense ao implementar o recurso (relevante para o trabalho!), É bom escrever nos comentários. Especialmente como tudo funciona, como uma classe é usada, qual é o propósito dessa enumeração e assim por diante. O objetivo é muito importante porque é difícil explicar por uma designação correta, a menos que alguém já conheça as convenções com antecedência.
Eu entendo que o "InjectorToken" tem todo o seu significado para você e que você poderia considerá-lo como "explícito". Francamente, é um bom nome. Mas quando eu vejo essa classe, eu quero saber o que é o token, o que ele faz, como eu posso usá-lo e o que é essa coisa de injetor. Seria ótimo ver isso nos comentários para que ninguém tenha que procurar em toda a aplicação, é?
Acredito que os comentários devem ser adicionados a cada função, incluindo construtores, a cada propriedade de classe, constante estática e a cada classe. É uma questão de disciplina. Quando você permite a preguiça, permitindo exceções aos comentários quando "algo não requer comentário, porque é auto-explicativo", a preguiça é muitas vezes o que você recebe.
O que quer que você pense ao implementar o recurso (relevante para o trabalho!), É bom escrever nos comentários. Especialmente como tudo funciona, como uma classe é usada, qual é o propósito dessa enumeração e assim por diante. O objetivo é muito importante porque é difícil explicar por uma designação correta, a menos que alguém já conheça as convenções com antecedência.
Eu entendo que o "InjectorToken" tem todo o seu significado para você e que você poderia considerá-lo como "explícito". Francamente, é um bom nome. Mas quando eu vejo essa classe, eu quero saber o que é o token, o que ele faz, como eu posso usá-lo e o que é essa coisa de injetor. Seria ótimo ver isso nos comentários para que ninguém tenha que procurar em toda a aplicação, é?
XXIV. A documentação▲
Eu sei, eu sei, eu odeio escrever documentação também. Se você escrever tudo o que sabe em seus comentários, a documentação pode ser gerada automaticamente por ferramentas. Além disso, a documentação pode fornecer uma maneira rápida de pesquisar informações importantes sobre a operação esperada do aplicativo.
Você pode usar o Doxygen para geração automática de documentação.
Você pode usar o Doxygen para geração automática de documentação.
XXV. Conclusão▲
Eu preferi um conjunto de princípios, não de regras, porque acho que há muitas maneiras de estar certo. Se você está convencido de que tudo deve ser abstrato, tente. Se você acredita que os princípios do SOLID devem ser usados em todas as aplicações ou se uma solução não é feita de acordo com um padrão de projeto conhecido, então é imediatamente ruim, está bem para mim.
Escolha o caminho que parece certo para você e sua equipe e cumpri-lo. E se você já estiver no clima experimental, experimente algumas das coisas mencionadas neste artigo. Espero que isso melhore a qualidade do seu trabalho. Obrigado por ler e pensar em compartilhar se você achou o artigo interessante.
Escolha o caminho que parece certo para você e sua equipe e cumpri-lo. E se você já estiver no clima experimental, experimente algumas das coisas mencionadas neste artigo. Espero que isso melhore a qualidade do seu trabalho. Obrigado por ler e pensar em compartilhar se você achou o artigo interessante.